

0.0.0.0 Day: Exploiting Localhost APIs From the Browser

Oligo Security's research team recently disclosed the “0.0.0.0 Day” vulnerability. This vulnerability allows malicious websites to bypass browser security and interact with services running on an organization’s local network, potentially leading to unauthorized access and remote code execution on local services by attackers outside the network.
The issue stems from the inconsistent implementation of security mechanisms across different browsers, along with a lack of standardization in the browser industry. As a result, the seemingly innocuous IP address, 0.0.0.0, can become a powerful tool for attackers to exploit local services, including those used for development, operating systems, and even internal networks.
The impact of 0.0.0.0 Day is far-reaching, affecting individuals and organizations alike.. The discovery of active exploitation campaigns, such as ShadowRay, further underscores the urgency of addressing this vulnerability.
Executive Summary
TL;DR
The Oligo research team has recently discovered a critical vulnerability affecting all major web browsers, enabling attackers to breach local networks. This finding, which we’ve dubbed "0.0.0.0 Day," exposes a fundamental flaw in how browsers handle network requests, potentially granting malicious actors access to sensitive services running on local devices.
Intro
Researchers at Oligo Security have disclosed a logical vulnerability to all major browsers (Chromium, Firefox, Safari) that enables external websites to communicate with (and potentially exploit) software that runs locally on MacOS and Linux. Windows is not impacted by this issue.
Oligo Researchers have found that public websites (like domains ending in .com) are able to communicate with services running on the local network (localhost) and potentially execute arbitrary code on the visitor’s host by using the address 0.0.0.0 instead of localhost/127.0.0.1.
Remediation In Progress: Browsers Will Soon Block 0.0.0.0
Following responsible disclosure, HTTP requests to 0.0.0.0 are now being added to security standards using a Request for Comment (RFC), and some browsers will soon block access to 0.0.0.0 completely. 0.0.0.0 will not be allowed as a target IP anymore in the Fetch specification, which defines how browsers should behave when doing HTTP requests.
Remediation Status By Browser
In the beginning of April 2024, Oligo disclosed these vulnerability findings to the security teams responsible for each of the major browsers.
The browser teams at each company have acknowledged the security flaw and will work on changing the related standard, and will also implement browser-level mitigations. Eventually, all browsers will block 0.0.0.0, but at the same time, the market demands a common standard to follow as well.
Due to the nature of the vulnerability and the complexity of the patch across browsers, it remains exploitable, allowing external websites to communicate with services on Localhost.
The lack of a finalized standard led to different implementations in different browsers. This means that every browser today handles HTTP requests to the internal or local network(s) in a different way.
Google Chrome (and Chromium-based browsers like Edge):
PNA (Private Network Access) is an initiative led by Google, and continues to evolve and improve. However, 0.0.0.0 vulnerability bypassed the PNA mechanism in Chromium, which blocks websites from accessing 127.0.0.1, localhost, and other private IPs via Javascript when loaded from public websites.
Following our report, Chrome is blocking access to 0.0.0.0 (Finch Rollout) starting with Chromium 128. Google will gradually roll out this change over the next few releases, completing it by Chrome 133, at which point the IP address will be blocked completely to all Chrome and Chromium users.

It is worth noting that the percentage of websites that communicate 0.0.0.0 is on the rise, based on counters in Chromium. Those pages could be malicious, and currently the percentage stands at 0.015% of all websites. With 200 million websites in the world as of August 2024, as many as ~100K public websites may be communicating with 0.0.0.0. The figure below illustrates this rise.

Apple Safari: Apple-based browsers including Safari are based on open source software called “WebKit.”
Following our report, Apple made breaking changes to WebKit that block access to 0.0.0.0. As part of this change, they added a check to the destination host IP address. If it is all zeros, the request is blocked. The specific changes can be found here: https://github.com/WebKit/WebKit/pull/29592/files
Our vulnerability report was addressed in the following releases:
- iOS 18 and iPadOS 18 public beta (22A3354 and later)
- macOS Sequoia 15 public beta (24A335 and later)
- tvOS 18 public beta (22J357 and later)
- watchOS 11 public beta (22R349 and later)
Mozilla Firefox: As of now, there is no immediate fix in Firefox. Although a fix is in progress, Firefox has never restricted Private Network Access, so technically it was always allowed. From this perspective, is “nothing to fix” since PNA is not implemented in the first place.
Following our report, Mozilla has changed the Fetch specification (RFC) to block 0.0.0.0. Firefox has prioritized the implementation of Private Network Access, but it is not implemented yet. At an undetermined point in the future, 0.0.0.0 will be blocked by Firefox and will not depend on PNA implementation.
0.0.0.0 Day - A Deeper Dive
Introduction
Browsers—we’ve all got a favorite, and we all use them daily. Even non-browser applications often load resources from external domains, like when using Google Analytics and similar client-side SDKs or embedding scripts or videos.
Browsers have always been a security target, driving browser developers to introduce groundbreaking security concepts like sandboxing and HTTPS-ONLY cookies, or implementing Standards like CORS (Cross Origin Resource Sharing) around cross-site requests to secure servers and end-users All of these keep malicious websites using cross-site request forgery (CSRF) attacks far away from users’ private data, internal networks, and local applications.
Browsers, by design, can send a request to almost any HTTP server using Javascript. When handling a cross-site response, the browser’s security mechanisms decide which action to take:
- Valid: Propagate the response data to the Javascript context (success)
- Invalid: Return a masked response or raise a special error (CORS, SOP, …).
But sometimes, the response does not matter at all.
With the 0.0.0.0 Day vulnerability,, a single request can be enough to cause damage. Before we get into the particulars, there’s a bit of background to understand.
A Most Unusual IP: What Is 0.0.0.0, Anyway?

Let’s go back to where the problem begins: 0.0.0.0 has “multiple uses.”
You may already be thinking of some of them: “all the IPs on this host,” “all the network interfaces on this host,” or simply “localhost.”
RFC 1122 refers to 0.0.0.0 using the notation {0,0}:
It prohibits 0.0.0.0 as a destination address in IPv4 and only allows it as a source address under specific circumstances, like when used in DHCPDISCOVER packet during DHCP handshake, when an IP is allocated for the first time. 0.0.0.0 is sometimes used in /etc/hosts files to block certain domains (serving as an adblock) or, when used in networking policies, the CIDR blocks 0.0.0.0/32—all IPs are allowed.
Why is this website port scanning me?
Digitally “fingerprinting” the users of a website is a known technique that has many purposes. The most common legitimate use is to identify returning users, but the technique can also be used by threat actors to gather intelligence for phishing campaigns. When cross-validated with additional data about the user, websites can tell a lot about who is currently visiting—even if you’ve never logged in.
In May 2020, an interesting headline appeared on Hacker News:

In this case, Ebay apparently tried to port scan the visitor as soon as the website loaded. Using this technique, the website used Javascript to scan the ports on localhost (127.0.0.1), resulting in an interesting, unique fingerprint.

Browsers should not have the ability to send those requests in the first place. Why? Because a single request could lead to exploitation (as we’re about to show in this blog). This was just the way the internet worked for years, and no one cared. It took time to fully understand that this behavior could lead to breaches—and by the time we found out, it was part of every browser, and very hard to fix.
An 18-year-old bug?
Local and internal services have always been a major attacker target.
A particular interesting security issue was reported to Mozilla, takes us back to 2006, before Chrome’s first release in 2008:

In this bug report, a user claimed public websites had attacked his router in the internal network, and believed websites should not be able to do so.
At that time internal networks (and the internet in general) were insecure by design: many services lacked authentication, not to mention SSL certificates and HTTPS, which did not exist everywhere. Websites were loaded over insecure HTTP transport, and attackers constantly outsmarted the browser for malicious purposes.
Since 2006, numerous attack campaigns have leveraged the fact that requests are still dispatched, while browsers focus on responses. By using malicious Javascript in an attacker-controlled website, for instance, attackers could alter your home or office router configuration.
Eighteen years have passed, with hundreds of comments, but the bug remains open to this day.
During these 18 years, this issue was closed, reopened, reprioritized to “severe” or “critical,” and even exploited in the wild.

The maintainers had a tough time agreeing on the nature of the bug:
- Is it a “vulnerability”?
- Is it specific to Firefox?
- Is it a request for enhancement?
Some Firefox maintainers claimed it was neither a bug nor a feature. The bug report was closed, reopened, then prioritized—and will now remain open until Firefox implements PNA.
A single HTTP request was enough to trigger the bug—the response did not matter. Example malicious script tags were already documented in 2006, in the wild, targeting home routers:




Lack of standardization was the main source of all this pain—creating an obvious need to develop a baseline security mechanism in all browsers. The world yearned for a standardization that extended Cross Origin Resource Sharing (CORS) in all major browsers, allowing them to distinguish between local, private, and public networks.
Google stepped boldly into the gap with Private Network Access.
What is PNA (Private Network Access)?
For a long time, it was not clear how browsers should behave when they make requests to local or internal networks from less-private contexts. Domains like attacker.com should not be able to contact localhost—not in any real world scenario.
All major browsers have relied on CORS. CORS helps a lot, but its performance depends on the response content, so requests are still made and can still be sent. This is simply not good enough. History proved that a single HTTP request can attack a home router—and if that’s all it takes, every user needs to be able to prevent this request from happening at all.
Luckily for all of us, Chrome introduced PNA (Private Network Access):

This new standard extends CORS by restricting the ability of websites to send requests to servers on private networks.
PNA proposes to distinguish between public, private, and local networks. Pages loaded under a less-secure context will not be able to communicate with more-secure contexts. For example, attacker.com is not able to contact 127.0.0.1 or 192.168.1.1 because these IP addresses are considered more private.

PNA is different from CORS. While CORS only protects unintended content from being loaded on unsafe contexts, it does it at the response level. The resources used by the response are masked or dropped. PNA strengthens this capability by introducing the ability to prevent the request from being sent at all.
Putting 0.0.0.0 To the Test: PNA Bypass
According to the current PNA specification, the following IP segments are considered private or local:

During our research, we noticed that “0.0.0.0” was not on this list. We believed that as part of PNA websites could not dispatch requests to 0.0.0.0. According to the specification, It should not be used as a target.
To find out, we ran a dummy HTTP server on localhost (127.0.0.1).
We then tried to access it through an external domain from Javascript, using 0.0.0.0.

It … simply worked. The request reached the server.
What happened here?
1. Under public domain (.com), the browser sent the request to 0.0.0.0.
2. The dummy server is listening on 127.0.0.1 (only on the loopback interface, not on all network interfaces).
3. The server on localhost receives the request, processes it, and sends the response.
4. The browser blocks the response content from propagating to Javascript due to CORS.
This means public websites can access any open port on your host, without the ability to see the response.
We understood this was a bypass of the current PNA implementation and an inherent flaw in browsers. We reported what we found to all browsers, following responsible disclosure, but we needed a real threat and a real attack vector to prove our point.
Finding vulnerable local applications
First, we needed to find an application that was in potential trouble—and we were spoiled for choice. Many applications are likely to be impacted by the 0.0.0.0 Day vulnerability.
When services use localhost, they assume a constrained environment. This assumption, which can (as in the case of this vulnerability) be faulty, results in insecure server implementations. For example, many applications skip CSRF token challenges and compromise on authorization or authentication because they are supposed to run in a strictly controlled network environment.
In some cases, no authorization or authentication may be required, or there may be no verification of CSRF tokens. When the app sees indications that it is running in a safe environment, or a trusted, isolated network, it allows POST HTTP routes that lack authorization or CSRF tokens, and write access to resources and configurations—allowing code execution. Even a single HTTP request can be enough to allow access to your ports.
To find a local application that would be vulnerable from the browser, first we needed an HTTP Server that runs on a local port (localhost network interface).
To fully exploit that vulnerability by gaining remote code execution, we needed the service to have an HTTP route that could write, tweak, or modify files and configurations. Again, we were spoiled for choice: real-world applications have many endpoints, and local services do make those security compromises, which is great news—for attackers.
It wasn’t long before we had our first vulnerable application: Ray.
POC: ShadowRay From the Browser
ShadowRay, a recent attack campaign targeting AI workloads, was discovered by Oligo in the wild. Our researchers have now proven that it is possible to execute this attack from the browser, using 0.0.0.0 as the attack vector.
ShadowRay enabled arbitrary code execution when unintentionally exposed to the internet, and went undiscovered for nearly a year. As big fans of Ray, we have often used it locally for development. With that in mind, we asked ourselves: “Could a public website exploit a Ray cluster running on localhost?”

Explanation: First, in the right terminal, we run a local Ray cluster on localhost. Then, on the left terminal, we start a socket that is listening to new connections, to open a reverse shell. Then, the victim clicks on the link in the email, which runs the exploit. The exploit opens a reverse shell for the attacker on the visitor’s machine.
Here is the example code that was used for the exploit


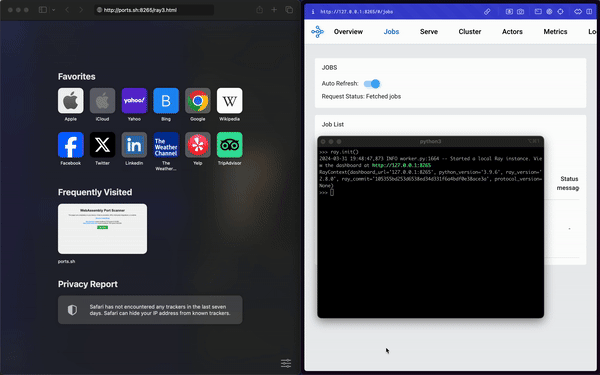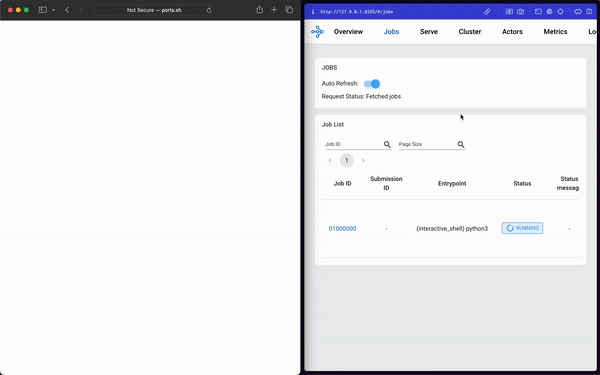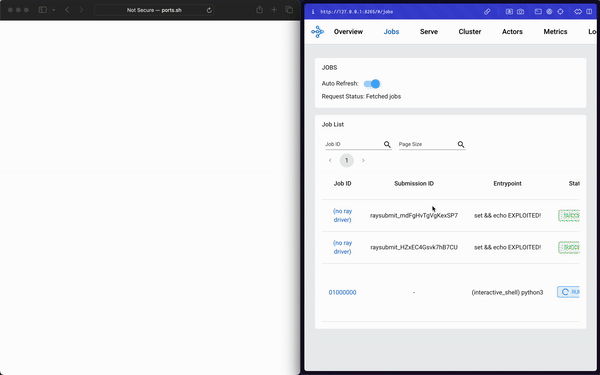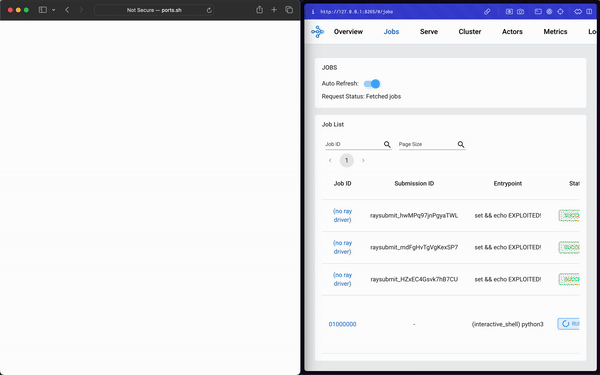

Once again…it just worked.
It was too easy. We realized instantly that executing ShadowRay from the browser is just one of an undoubtedly huge number of Remote Code Execution attacks enabled by this approach—so we decided to search for more.
Selenium Grid
Recent attack campaigns such as SeleniumGreed showed threat actors leveraging Selenium Grid public servers to gain initial access to organizations, using known Remote Code Execution vulnerabilities.
On local Selenium Grid instances, we discovered that RCE is possible when dispatching a POST request to http://0.0.0.0:4444/ with a crafted payload.

Another interesting attack vector: using the local Selenium Grid cluster to browse to websites using insecure browser configurations, to gain access to internal domains and private DNS records behind a VPN.
Pytorch Torchserve (ShellTorch)
In July 2023, the Oligo Research Team disclosed multiple new critical vulnerabilities to Pytorch maintainers Amazon and Meta, including CVE-2023-43654 (CVSS 9.8). These vulnerabilities, collectively called ShellTorch, lead to Remote Code Execution (RCE) in PyTorch TorchServe—ultimately allowing attackers to gain complete, unauthorized access to the server.
AI practitioners who use TorchServe in an internal network (locally or using port-forwarding), These vulnerabilities can be leveraged through 0.0.0.0 as well, leading to compromisation of the local TorchServe cluster that is behind firewalls and WAF.
Identifying Returning Users Based On Open Ports
Another interesting attack vector is the ability to recognize anonymous users—especially users who have no cookies and have never logged in—by port scanning them. The results of the local port scan can be cross-validated with more data such as User-Agent, IP address, and other identifiers (like https://amiunique.org/ emphasizes). The following ports are used by different personas inside the organization.
- TeamViewer (port 5938)
- Selenium Grid (port 4444)
- Ray (port 8265)
Conclusion: How Local Is Your Localhost?
PNA is fantastic—a truly amazing effort led by Google and the community. But until PNA fully rolls out, public websites can dispatch HTTP requests using Javascript to successfully reach services on the local network. For that to change, we need PNA to be standardized, and we need browsers to implement PNA according to that standard.
CORS is also great, and already makes the internet much safer. CORS prevents the responses from reaching the attacker, so attackers cannot read data when making invalid requests.
When submitting a request, If the CORS headers are not present in the response, the attacker’s Javascript code will not be able to read the response’s content.
CORS would only stop the response before it propagates to JavaScript, but opaque requests can be dispatched in mode “no-cors” and reach the server successfully—if we don’t care about the responses.
In our demonstration, we proved that by using 0.0.0.0 together with mode “no-cors”, attackers can use public domains to attack services running on localhost and even gain arbitrary code execution (RCE), all using a single HTTP request.
Thanks to our reports, browsers prioritized those fixes and made breaking changes, blocking 0.0.0.0 as target IP. It was important to have a collaborative fix to avoid a situation in which browsers would “zero-day each other” by introducing a fix.
How Can I Protect Local Applications From 0.0.0.0-Day?
Obviously, waiting for a browser fix isn’t ideal—so there are some things developers can do to protect local applications.
Here are our biggest pointers:
- Implement PNA headers
- Verify the HOST header of the request to protect against DNS rebinding attacks to localhost or 127.0.0.1.
- Don’t trust the localhost network because it is “local”—add a minimal layer of authorization, even when running on localhost. Jupyter Notebook developers did a great job at this, adding a token by default.
- Use HTTPS when possible.
- Implement CSRF tokens in your applications, even if they are local.
- Remember that browsers act as gateways, and they have routing capabilities to internal IP address spaces in many browsers.
References
[1] https://www.forbes.com/sites/thomasbrewster/2024/08/07/hackers-exploit-18-year-old-vulnerability-in-apple-google-and-mozilla-browsers/
[2] https://bugzilla.mozilla.org/show_bug.cgi?id=354493
[3] https://groups.google.com/a/chromium.org/g/blink-dev/c/9uymCQNGVgw/m/TxWeILuJAwAJ
[4] https://chromestatus.com/feature/5106143060033536
[5] https://developer.chrome.com/blog/private-network-access-preflight
[6] https://en.wikipedia.org/wiki/0.0.0.0#cite_ref-12
[7] https://support.apple.com/en-il/121238
[8] support.apple.com/en-us/121250
[9] support.apple.com/en-us/121249
[10] support.apple.com/en-us/121248
[11] support.apple.com/en-us/121240
[12] support.apple.com/en-us/121238